MUStReason: A Benchmark for Diagnosing Pragmatic Reasoning in Video-LMs for Multimodal Sarcasm Detection
LREC 2026
Abstract
Sarcasm is a specific type of irony which involves discerning what is said from what is meant. Detecting sarcasm depends not only on the literal content of an utterance but also on non-verbal cues such as speaker's tonality, facial expressions and conversational context. However, current multimodal models struggle with complex tasks like sarcasm detection, which require identifying relevant cues across modalities and pragmatically reasoning over them to infer the speaker's intention. To explore these limitations in VideoLMs, we introduce MUStReason, a diagnostic benchmark enriched with annotations of modality-specific relevant cues and underlying reasoning steps to identify sarcastic intent. In addition to benchmarking sarcasm classification performance in VideoLMs, using MUStReason we quantitatively and qualitatively evaluate the generated reasoning by disentangling the problem into perception and reasoning. Further, we propose PragCoT, a framework that steers VideoLMs to focus on implied intentions over literal meaning, a property core to detecting sarcasm.
MUStReason
Existing sarcasm detection datasets like MUStARD provide only coarse-grained binary labels and lack fine-grained annotations indicating which specific modalities or cues contribute to making the utterance sarcastic. MUStReason bridges this gap by automatically curating reasoning-aligned annotations that enable detailed evaluation of modality perception and inference failure which are key factors for assessing and improving pragmatic reasoning in multimodal models.
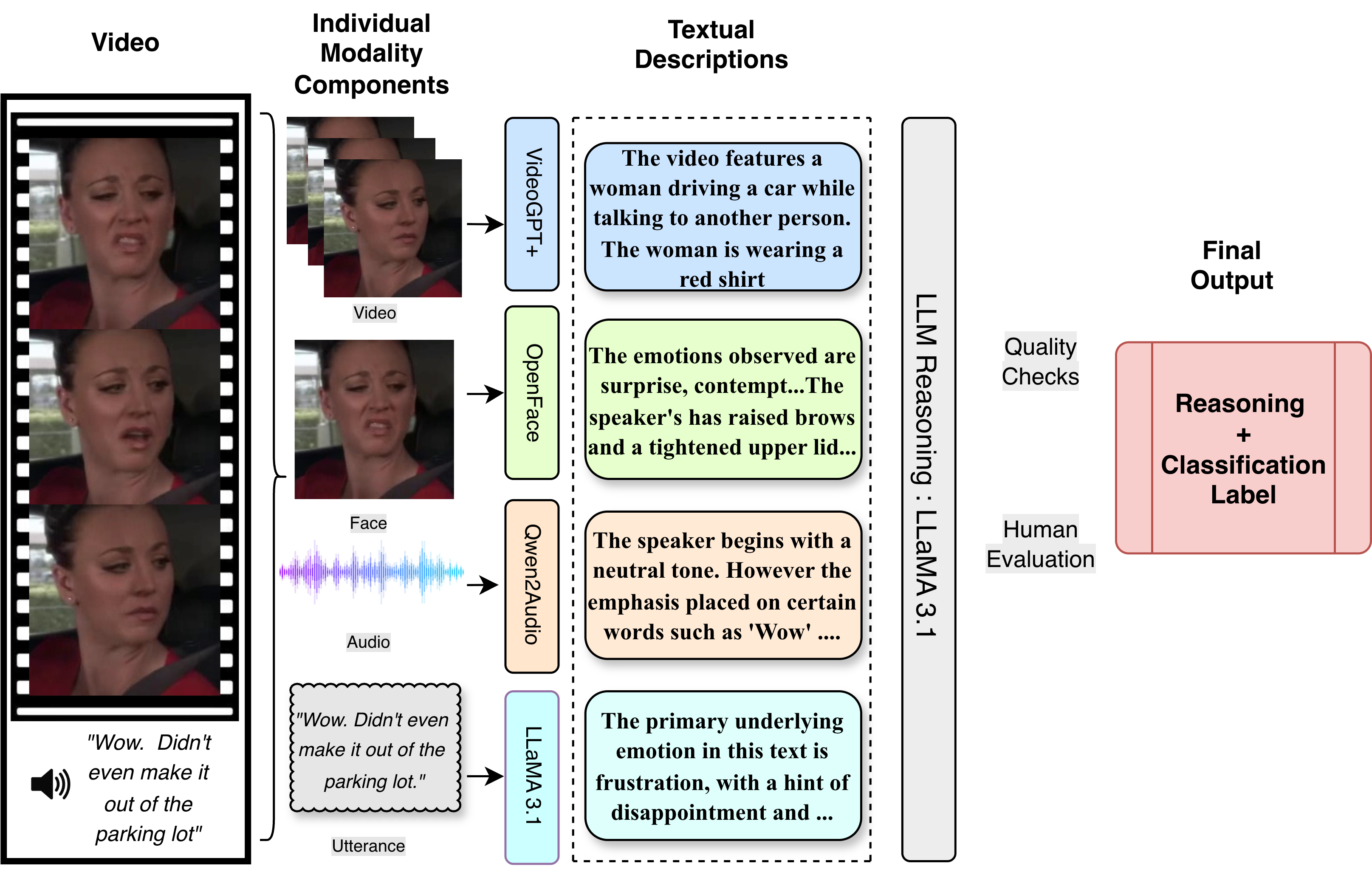
PragCoT
Pragmatic reasoning relies heavily on contextual cues, social dynamics, and the viewer's interpretation of a situation, focusing more on the underlying intent rather than the literal meaning. To allow VideoLMs to pragmatically reason about sarcasm, we propose PragCoT, which accomplishes this by systematically breaking down the task into three steps: Perception, Decoding, and Reasoning.
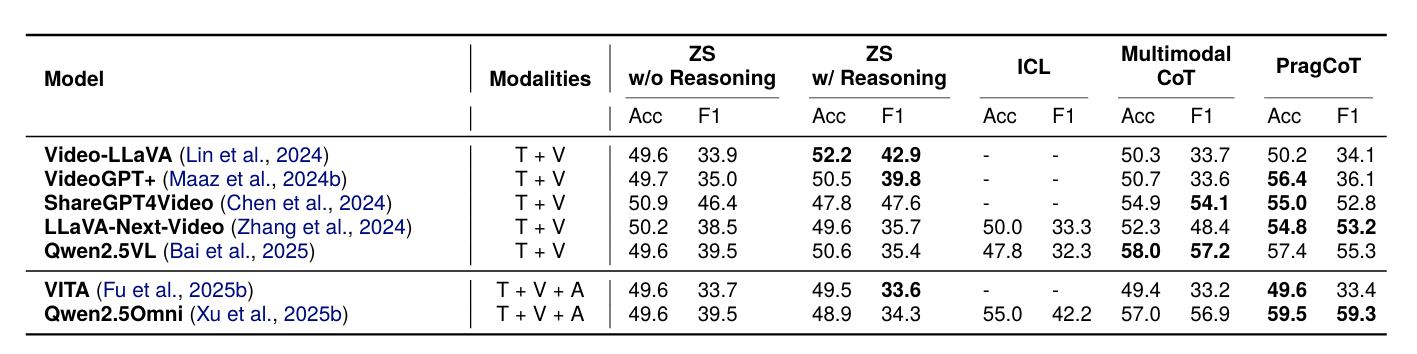
Performance of Video-Language Models on Sarcasm Classification
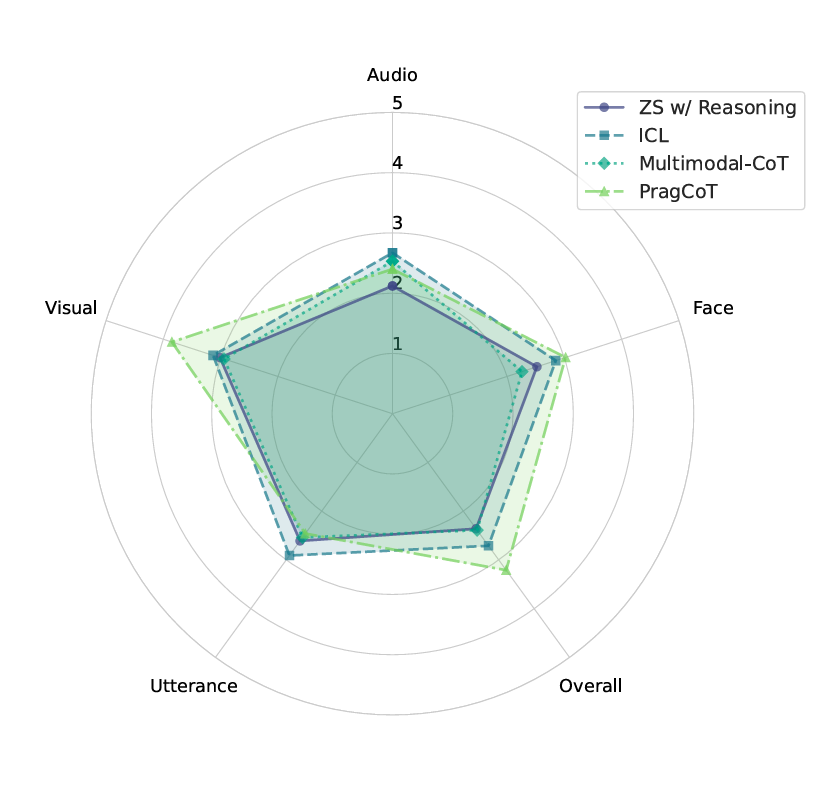
Qualitative Evaluation of Model-Generated Reasoning using Annotations from MUStReason
BibTeX
@misc{saha2025mustreasonbenchmarkdiagnosingpragmatic,
title={MUStReason: A Benchmark for Diagnosing Pragmatic Reasoning in Video-LMs for Multimodal Sarcasm Detection},
author={Anisha Saha and Varsha Suresh and Timothy Hospedales and Vera Demberg},
year={2025},
eprint={2510.23727},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.23727},
}